
Why Knowledge Graphs Suddenly Matter Again (Especially for AI)#
A few days ago I listened to a podcast episode about knowledge graphs, ontologies and semantics. One of those episodes where you start with “yeah yeah, sounds academic” and end up thinking “wait… this explains half of the problems we currently have with AI”.
This post is my attempt to structure and digest what I learned. If you are curious, you can find the podcast episode here.
A big shoutout to Tobias from Tentris.io and also to Heisenware as the podcast hosts. The discussion was genuinely insightful and highly relevant for anyone building data driven or AI powered systems today.
From relational tables to connected knowledge#

Most of us grew up with relational databases. Tables, rows, columns, foreign keys. SQL joins everywhere. And to be fair: relational databases are amazing at what they do. Transactional workloads, clear schemas, predictable queries.
But they start to struggle once relationships become the core of the problem.
Imagine dozens of tables, joined again and again, just to answer questions like:
- Who is related to whom?
- What belongs together?
- How does A influence B indirectly?
At some point the query becomes harder to read than to explain in plain English. And performance usually suffers as well.
This is exactly where knowledge graphs enter the stage.
A knowledge graph stores information as nodes and edges. Or in simpler terms: things and their relationships. Instead of flattening knowledge into tables, you model it closer to how humans actually think about the world. More like a big structured mind map.
Ontologies: the missing layer of meaning#
What really made it click for me was the role of ontologies.
An ontology defines what things are and how they are allowed to relate to each other. For example:
- A car is a vehicle
- A car has exactly one engine
- An engine is not a vehicle
- An electric car is a car
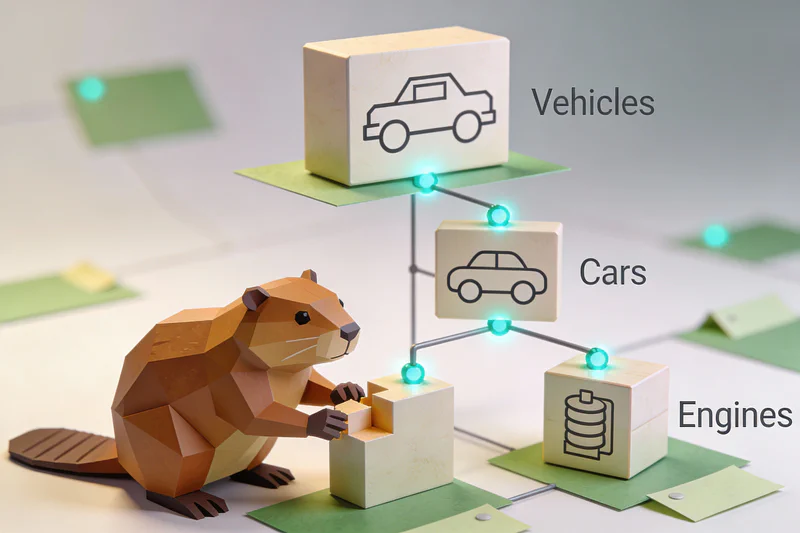
This may sound trivial, but it introduces something most databases do not have: formal semantics.
Instead of just storing data, you store meaning and rules. The data inside the graph then follows this structure. Technically this is often represented as triples:
Subject - Predicate - Object
For example:
CarA - hasEngine - Engine1
Once this structure exists, machines can start reasoning about data instead of just retrieving it.
Why graphs outperform joins at scale#
Relational databases can model relationships. But every additional join increases complexity and cost. Deeply connected data quickly becomes painful.
Graph databases are optimized for exactly this problem. Traversing relationships is cheap. Asking questions like “show me all entities connected within three hops” is a natural operation, not an edge case.
That does not mean graph databases replace relational ones. Each has its sweet spot:
- Relational databases: structured data and transactions
- Document stores: scalability and flexibility
- Vector databases: similarity search
- Knowledge graphs: relationships and semantics
There is no silver bullet. Only better tools for specific problems.
Real world examples you already use#
One of the nicest parts of the podcast was how grounded the examples were.
You are probably using knowledge graphs every day without knowing it:
- Netflix recommendations
- Spotify music discovery
- Google search and knowledge panels
- Large ecommerce platforms that actually understand what you are looking for
In the episode, Netflix was contrasted with Amazon Prime. Not as a product comparison, but as an architectural one. Netflix heavily relies on knowledge graphs to connect users, content, genres, actors and behavior. This allows both better recommendations and better business decisions.
Knowledge graphs meet AI#
This is where things get really interesting.
Most current AI systems use Retrieval Augmented Generation. Documents are chunked, converted into vectors and stored in vector databases.
Queries are matched via similarity search and the retrieved chunks are injected into the prompt.
This works surprisingly well for small and medium datasets.
But it has limitations:
- No real understanding of relationships
- No explainability
- Increasing noise with growing data
The podcast introduced the idea of Graph RAG.
Instead of retrieving chunks purely by vector similarity, the system first navigates a knowledge graph. The ontology already encodes structure and meaning. The retrieved subgraph is then passed to the language model.
The benefits are huge:
- Far fewer hallucinations
- Explainable results, because the graph path is visible
- Better scaling across different domains and data silos
A vector space can tell you what looks similar. A knowledge graph can tell you what is related and why.
Why this suddenly matters now#
Knowledge graphs are not new. The idea goes back to the early days of the Semantic Web.
What is new is the combination with modern language models.
LLMs are fantastic at language. But they are not knowledge systems. They need structured, meaningful context. Knowledge graphs can provide exactly that.
In a way, LLMs become the voice. Knowledge graphs become the memory.
Where this goes next#
This post is intentionally conceptual. I wanted to first understand why knowledge graphs are relevant again before touching code.
In the next post I want to explore this hands on:
- Build a tiny knowledge graph
- Define a minimal ontology
- Query it from a .NET application
- And eventually combine it with an AI workflow
Because as always: things only really click once you build them yourself.